Who's ready to jump into a self-driving car?
January 04, 2017
Safety is a major concern for self-driving cars. In constant motion, their perception of the vehicle environment is one of the most challenging tasks...
Safety is a major concern for self-driving cars. In constant motion, their perception of the vehicle environment is one of the most challenging tasks for engineers.
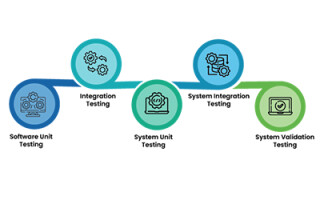
To understand the whole process involved, let’s review the decision channel (Figure 1). It all begins with various sensors that provide information about the environment surrounding the vehicle, as well as the vehicle itself. This info is then assessed – obstacle detection, lane detection, position, analysis of the surrounding objects’ dynamic (e.g speed of car ahead), as well as traffic signs and path optimization. This info helps decide how to actuate the vehicle, and precisely control its position and dynamics.

[Figure 1 | Functional partitioning of a decision structure in a car[1].]
This simplified process implies several major challenges for self-driving cars. First, this structure assumes that the sensor information is shared among the different key functions in order to produce a consolidated and unique model of the vehicle state. In other words, this assumes centralized computation architecture, a quite different approach than today’s cars, in which functions are clustered into isolated computing units. Second, this partitioning requires a considerable amount of computing power. And therein lies the problem: this centralized amount of computing power is still not available in cars that provide typical drivers with self-driving features.

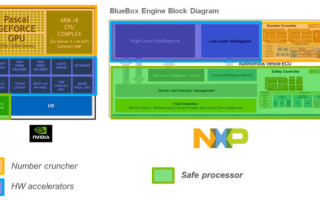
[Figure 2 | Example of ADAS computing architectures.]
Today, there are several potential computing architectures like NVIDIA PX Drive 2 and NXP BlueBox (Figure 2). These platforms contain a parallel computing part called “number cruncher”, dedicated to processing the huge amount of data received from sensors (in orange, Figure 2). In addition, hardware accelerators improve the performance of some specific functions.
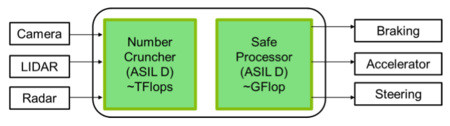
Last but not least, and perhaps one of the most critical parts, a “safe” processor ensures that the decision applied to car actuators is made in a unit responding to the highest automotive certification levels (e.g. ISO26262 ASIL-D). Mapping the partitioning of Figure 1 into these architectures leads to a scheme like that shown in Figure 3. The intensive data processing done with sensor input is ensured by the number cruncher function that provides several TFlops of computing power. The decision is applied by a safe processor with some GFlops of computing power.

[Figure 3]
The commands are thus made by a less powerful processor, but with strong functional safety guarantees. The problem is that part of the decision chain has a lower level of functional safety. So, how to assess the entire system? A first solution can be redundancy (Figure 4). However, complexity[2] and cost impacts are important.

[Figure 4]
Another approach is to propose a breakdown solution to guarantee functional safety in the number-cruncher part (Figure 5). Today, several technical and theoretical issues prevent this solution from being available in the near future.
[Figure 5]
Working at algorithm level should be taken into account to require less power computing for the same functions. What if we could reduce the complexity of each function by a factor of 10, 100 or 1,000? This should help fit critical functions into already certified processors and leave the number cruncher to ensure complementary functions. SIGMA FUSION proposes an algorithm that helps go in this direction. It solves the range-sensor fusion problem that is required to ensure environment perception. It fits into a single processor offering a few GFlops of computing power that is equivalent to today’s automotive certified processors.
So now, who’s ready to jump into a self-driving car?
References
1. Henrik Lind, Volvo Cars, Sensors for highly automated vehicles: the Drive Me project
2. Fallback Strategy for Automated Driving using STPA. T. Raste, Continental, 3rd European STAMP Workshop, Amsterdam, Oct. 6, 2015.